
梦瑶 发自 凹非寺
全球齐懂,视频生成这件事,最让创作家头疼的,不一定是画面不够清澈。
而是模子常常听不懂东说念主话!!!(扎心.jpg)
想把好天改成雪天,它可能只会往画面上撒雪花;想把一段动画植入市集LED大屏,它可能规模乱飘、透视不稳。
于是乎,问题来了:AI视频生成,能不成先贯串创作家到底想改什么,再脱手生成?
就在刚刚,字节买卖化手艺团队反手给出一个行业新解法——
开源面向视频生成与视频剪辑的长入框架:Bernini。
主打一个先贯串再生成~

Bernini的想路很奏凯,让多模态大模子先正经语义贯串与绸缪,再交给diffusion模子完成高质地视觉渲染。
在才能上,Bernini遮掩了参考生成、视频剪辑等多种任务,重点体现的即是两个字:「可控」。
比如更正举座视觉格调时,不仅仅把单帧画得排场,还能稳住前后帧的一致性,主打一个效用超等稳:

这下好了,AI视频生成也能从听prompt干活,往先贯串、再脱手再进一步了~
对了,当今,Bernini的推理代码和权重还是通达!!(喜跃.jpg)
一条指示改视频,Bernini放肆拿抓「可控剪辑」!
淌若说夙昔好多视频生成模子更像按教唆词出片,那Bernini想惩办的,是另一个更骨子的问题——
生成之后,怎样继续改?
咱们平淡碰到的大大宗治疗需求听起来齐很easy,但对视频模子来说并不通俗!!!
因为视频剪辑不是改一张图,而是在一段一语气画面里,既要听懂指示,又要保住主体、结构、镜头和通顺酌量。
略微处理不好,就会出现主体变形、配景漂移、动作断裂、帧间精明等问题。
而Bernini的中枢想路,恰是把这个过程拆得更清澈。

△AI生成
咱们不错把Bernini贯串成一个AI视频片场里的「导演+后期团队」。
前边正经导演的,是一个叫MLLM-based planner的多模态大模子绸缪器。
它会先看懂你的文本指示,也会沿途贯串源视频、参考图片、参考视频这些素材,判断办法画面应该形成什么样。
等这一步想清澈后,再交给diffusion模子DiT-based renderer来完成视觉渲染,把前边绸缪好的语义办法,着实形成一语气、贯通、高质地的视频画面。
是以Bernini框架的妙处,就在于单干弥散清澈:
多模态大模子正经想显明,Diffusion Transformer正经生成出来。
从文本到视频生成,到视频剪辑,再到基于图像和视频参考的复杂限度生成完好部梭哈!

△Bernini在长入框架内缓助多种视频生成任务
这套好意思妙单干,也让Bernini在视频可控剪辑上,展现出了一批独特直不雅的视频剪辑才能。
最基础的,是一条指示更正天气、季节、材质和格调的才能。
比如合并段城市航拍视频,输入指示后,不错从好天切到雾天、雨天、雪天。
最重要是,它处理的并不仅仅天上多几片雪、画面加一层滤镜,而是会连带治疗天外、光照、路面、成扬名义和举座环境氛围,让这场天气变化看起来像确凿发生在原场景里:

更进一步,Bernini的语义剪辑还是初始参加「镜头说话」。
当先即是能限度画面关爱区域的视角、焦点和动作。
在视角剪辑上,Bernini能进一步贯串场景里的三维酌量,让部分视角治疗落幕更适宜透视、结构和空间逻辑:

在焦点剪辑才能上,Bernini还粗略把柄指示治疗画面的关爱区域,让视频叙事要点随之更正。
比如一个画面里有多个物体,咱们不错让镜头更关爱桌上的收音机,也不错让焦点从远景转到配景,so easy~

诚然,视频创作里最容易卡bug的,还有动作。(doge)
毕竟好多AI视频静止看还行,一动起来就显露:主体变形、动作断裂、配景漂移,镜头也随着不稳!!
值得一提的是,Bernini在保留主体身份和场景结构的前提下,不错高精确度地更正主体动作步履。
咱们来看底下这段棕熊视频,哪怕从庸碌景况改成起身舞蹈、吼怒,188金宝博官网app下载环境、光照和镜头酌量依然能保持贯通~

这就意味着,Bernini改视频不仅仅让主体「动起来」,还要让动作变化「当然嵌进」原来的画面里。
从反复抽卡到那里不合改那里,AI视频终于初始有点后期软件的味儿了???
参考素材上场,视频创作更可控、更一致
友友们平淡作念AIGC内容创作时,还会遭遇一个问题,那即是——
咱们确凿很难用一句prompt,精确时势想要的视觉效用……
尤其是碰到具体材质、某个商品、某种电影色彩,或者一段需要植入到屏幕里的视频素材,就更容易翻车…..
好巧不巧, Bernini除了剪辑的要道很强外,还有一个贼实用的才能:缓助图片和视频行为剪辑参考。
不仅如斯,它还能基于参考输入奏凯生成新视频,把物体、变装和场景的一致性问题狠狠拿抓!!
不单靠prompt:用图片和视频行为剪辑参考
当先来看Bernini参考生成的第一个要道——剪辑参考。
具体来说,Bernini不错让创作家奏凯用视觉样例限度落幕,告白创意、电商展示、影视预演、二次创作友友狂喜!!
比如底下这个加多指定主体的案例,只需要放入一张狗狗参考图,视频里就能当然出现同款狗狗。
再输入一张雪东说念主图片,雪东说念主也能顺滑融进当前视频里,光照、透视、旯旮酌量齐处理得相等当然:

除了参考主体,Bernini还能参考材质。
比如给它布料、朱砂壶、大理石、金属等不同材质参考,原视频里的盘子就不错被改成对应纹理视觉质感~
况兼最重要的是,这种材质变化会随着办法物体贯通存在,而不是播放几帧就漂移、错位或失真:

格调参考也不在话下!
哪怕参考图横跨卡通、写实、水墨、赛博一又克等完全不同的视觉格调,Bernini也能索求格调特征并转移到视频里。
值得一提的是,原视频里的主体和通顺酌量也会高度保留,格调变化也会随着时刻轴贯通延续:

此外皮剪辑参登第,Bernini还有一类很实用的才能,那即是:图像与视频植入。
全球齐知说念,街头灯箱、市集LED大屏、地铁电视,致使镜头里任何一块屏幕,2026美加墨世界杯中国认证平台齐不错形成展示位。
而Bernini能作念的,即是把一张海报、一段视频精确填进办法区域里,还能随着原片镜头沿途转移,作念到规模不破、透视不乱、时序不抖。
举例给一段街头实拍再提供一张油绘画片,Bernini就能把油画当然贴进牌号里,画面交融度也相等强:

告白预览、影视预演、造谣拍摄里,好多蓝本要反复抠帧、追踪、校透视的责任,这下也能被收进了一次推理里了~
顺带提一嘴,除了剪辑已有视频,Bernini还缓助基于参考图奏凯生成「新视频」。
咱们先来看全球平淡需求比拟多的单图参考生成。
比如只给一张香水居品图,再输入「生成一段居品展示视频」的教唆词,模子就能生成真东说念主手持香水动弹的画面。
瓶身概括、金色液体、玄色标贴这些重要细节,齐能和原图保持很高的一致性。
更挑升义的是,换成一条通顺头带,再让模子摆脱施展,它还能生成一只羊驼戴着头带站在沙漠的画面:

合并个才能,既能作念正经居品片,也能搞脑洞创意短片,属实有点666了啊??
再进一步,Bernini还能已毕多元素组合参考生成。
在此我需要要大大点赞的少许是,咱们喂进去的参考图不一定需要来自合并个物体!!!
比如一座大理石半身像、一副粉色猫耳耳机、一件的玄色T恤、一条热带印花短裤,再加一张落日海滩长椅。
2026FIFA世界杯中国比分网几张图蓝本八竿子打不着,但Bernini却不错把它们组合成合并个视频变装:

(谁成想呢,NanoBanana那时大热的ootd玩法还是进阶到「视频」版块了!)
这类才能放到IP联名、造谣东说念主塑造、告白见识片里就很灵验,素材库里蓝本散布的元素,不错被从头组合成一个全新的变装和场景~
此外,Bernini还有一个更重要的才能,那即是合并物体的多角度参考。
全球齐知说念,商品和变装很少惟有一面,包有背带,车有尾灯,雕琢有侧脸和后头,模子淌若只看过正面,镜头一排,很容易初始摆脱施展。
而Bernini特殊就特殊在,它不错吃进合并物体的多张角度参考图——
比如喂给它大理石雕琢的五张多角度参考,再让它生成一段一语气镜头,雕琢从不同角度出刻下,五官、肌肉走向、衣袍褶皱齐能保持高度一致:

终末想说的才能,是场景重要帧到一语气镜头。
给到合并办公区休息廊的几张重要帧,比如沙发、绿植、走廊畸形的玻璃门,Bernini不错生成一段一语气平移镜头:

说真话,这一步还是初始接近更长线的寰宇模子才能了。
因为它老成的还是不仅仅这一帧好不排场,还包括模子能不成贯承接一个场景在一语气镜头里的空间酌量。
造谣漫游、游戏关卡生成、影视预演,致使具身智能模拟,往后齐绕不开这种一语气性。
从语义绸缪到视觉渲染,Bernini的重要是「先贯串,再生成」
是以问题来了,Bernini为什么能同期吃文本、视频、参考图,还能把落幕作念得更稳?
就像前边提到的,其中枢原因在于它莫得让一个模子包办扫数事情,而是把任务拆成了两步。
第一步是「语义绸缪」,让模子先贯串办法。
具体来说,Bernini当先使用MLLM-based planner来贯串文本、视频和参考视觉输入,并奏凯在ViT embedding space中预测办法语义示意。
这个办法语义示意,不错贯串成生成前的一张「语义草图」。
它不奏凯轨则每个像素长什么样,而是先时势清澈:办法视频应该包含什么内容、结构怎样变、哪些元素要保留、哪些场所要被剪辑。
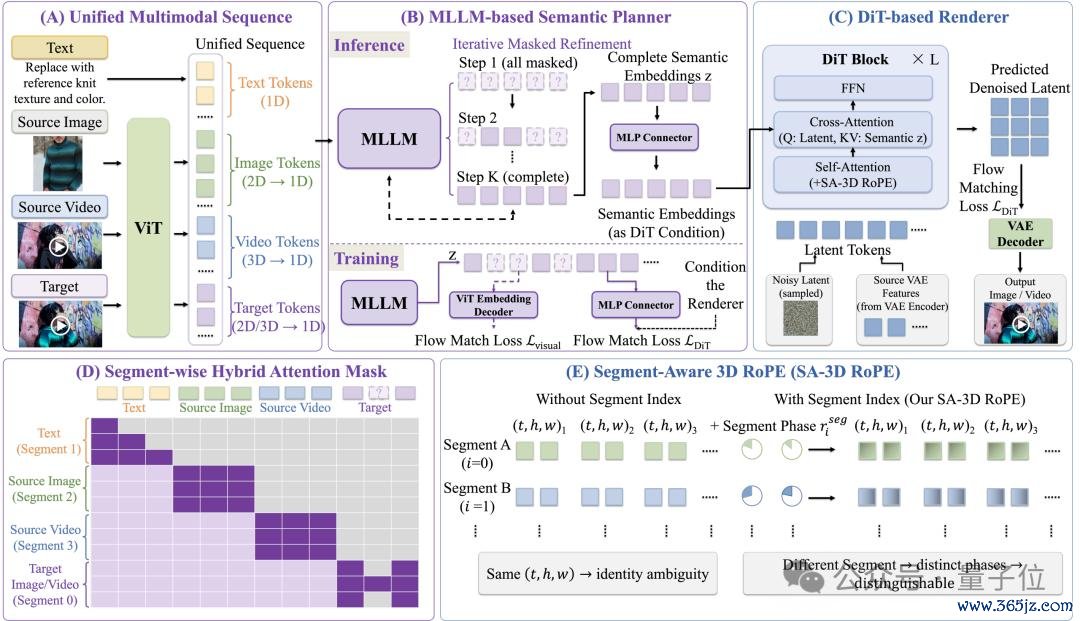
第二步是「视觉渲染」,把语义鼎新成高质地视频。
拿到语义绸缪后,DiT-based renderer会正经生成最终画面,关于视频剪辑任务,它还会纠合源视频的VAE features,尽量保留原视频里的细节和非剪辑区域,幸免一改就把整段画面带跑。
还有一个重要点,是「多参考输入」怎样处理。
当多个参考图、源视频、办法视频被串进合并个序列里时,不同素材可能会出现疏通的时刻和空间坐标,模子容易认混。
是以Bernini引入了Segment-Aware 3D Rotary Positional Embedding,也即是SA-3D RoPE。
它会给不同视觉片断加上各自的segment记号,让模子分清:哪个是参考图,哪个是源视频,哪个是办法输出;同期还能保留时刻和空间位置酌量。
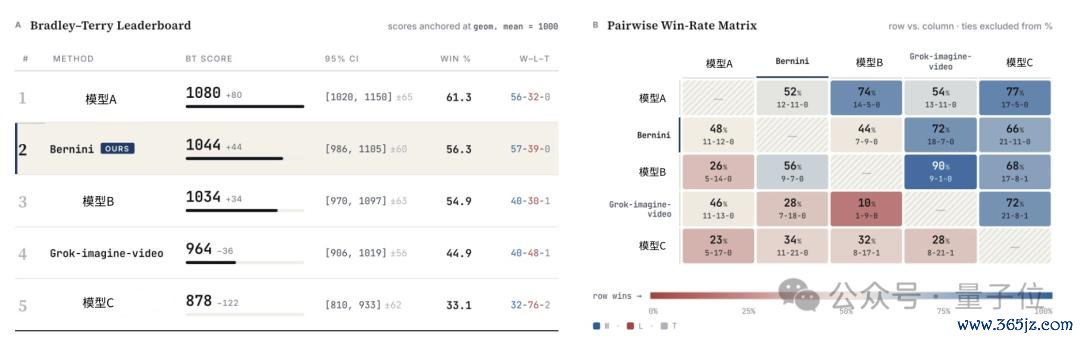
值得一提的是,在字节买卖化手艺团队自建的Arena落幕里,Bernini的位置也很有看头——
面临几款国表里主流闭源模子,这个开源框架莫得被拉开差距,反辛劳经站进了第一梯队:
说到底,Bernini最让创作家有实感的场所,不仅仅画面更排场,而是它让AIGC创作少了少许「玄学」。
以前咱们写了一大段prompt,AI有时懂;想改一个小场所,它可能整条视频齐重来;给了参考图,它也可能只学到少许外相,终末主体、材质、格调系数跑偏。
而Bernini惩办的,即是这种创作里的失控感。
它先贯串用户想要什么,贯串原视频里哪些内容要保留,也贯串参考图片、参考视频到底提供了什么视觉信息。
然后,再把这种贯串转成不错生成、不错剪辑、不错贯通落地的视频落幕。
少少许反复碰运说念,多少许着实可控的创作空间,这亦然Bernini最有价值的场所——
让全球用我方的素材、我方的想法,去探索AI视频创作还能怎样变得更好用、更听话、更接近着实创作历程。
对了,需要一提的是,当今率先开源的Bernini-R,对应Bernini三阶段检察历程中的第二阶段模子。
而包含MLLM Planner的完整版块也在代码整理中,预测近期将进一步通达,全球不错小小期待一下子!
(无论咋说,Bernini-R不错先狠狠安排上了~)
Bernini一箩筐参考链接:
[1]GitHub:https://github.com/bytedance/Bernini
[2]Hugging Face:https://huggingface.co/ByteDance/Bernini
[3]Project Page:https://bernini-ai.github.io2026美加墨世界杯中国认证平台